1. 系统整体架构
该系统是一个基于深度强化学习的体能训练权重优化平台,采用分层架构设计:
1.1 架构层次
┌─────────────────────────────────────────────────────┐ │ API服务层 (FastAPI) │ ├─────────────────────────────────────────────────────┤ │ 业务逻辑层 │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │权重优化服务 │ │权重预测服务 │ │模型训练服务 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ ├─────────────────────────────────────────────────────┤ │ 算法核心层 │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │PPO算法实现 │ │注意力机制 │ │神经网络模型 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ ├─────────────────────────────────────────────────────┤ │ 环境模拟层 │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │状态管理 │ │奖励计算 │ │权重更新 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ ├─────────────────────────────────────────────────────┤ │ 数据模型层 (Pydantic) │ └─────────────────────────────────────────────────────┘
1.2 核心数据流
用户输入 → 状态构建 → 环境初始化 → 策略网络 → 动作选择 → 环境交互 → 奖励计算 → 网络更新 → 权重输出
2. 核心算法设计
2.1 增强PPO算法设计
2.1.1 算法核心思想
PPO (Proximal Policy Optimization) 是一种先进的强化学习算法,通过限制策略更新幅度来确保训练稳定性。本系统在标准PPO基础上进行了多项增强:
2.1.2 算法流程
def ppo_update(self, states, actions, returns, advantages, log_probs_old):
# 1. 获取当前策略和价值估计
with torch.cuda.amp.autocast(enabled=self.use_amp and device.type == 'cuda'):
action_probs, values, cq_pred, qx_pred = self.actor_critic(states)
# 2. 计算重要性采样比率
dist = Categorical(action_probs)
log_probs_new = dist.log_prob(actions)
ratio = torch.exp(log_probs_new - log_probs_old)
# 3. 计算PPO损失 (Clipped Surrogate Objective)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - self.clip_ratio, 1.0 + self.clip_ratio) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
# 4. 计算价值损失 (使用Huber损失增强鲁棒性)
value_loss = F.smooth_l1_loss(values.squeeze(), returns)
# 5. 计算熵正则化项 (鼓励探索)
entropy = dist.entropy().mean()
entropy_loss = -self.entropy_coef * entropy
# 6. 计算CQ预测损失 (加权MSE)
true_cq = env.cq_matrix.unsqueeze(0).repeat(len(states), 1, 1)
cq_weights = torch.ones_like(true_cq)
cq_loss = torch.mean(cq_weights * F.mse_loss(cq_pred, true_cq, reduction='none')) * 50
# 7. 计算QX预测损失 (加权MSE)
true_qx = env.qx_matrix.unsqueeze(0).repeat(len(states), 1, 1)
qx_weights = torch.ones_like(true_qx)
qx_loss = torch.mean(qx_weights * F.mse_loss(qx_pred, true_qx, reduction='none')) * 100
# 8. 组合总损失
total_loss = (actor_loss +
self.value_loss_coef * value_loss +
entropy_loss +
self.cq_loss_coef * cq_loss +
self.qx_loss_coef * qx_loss)
# 9. 反向传播和优化
self._backward_and_optimize(total_loss)
return actor_loss, value_loss, cq_loss, qx_loss, entropy
2.1.3 关键增强技术
-
多目标优化:同时优化策略、价值、CQ预测和QX预测四个目标
-
损失权重平衡:通过精心调整的损失系数平衡各目标
-
混合精度训练:使用自动混合精度(AMP)加速训练并减少内存占用
-
梯度累积:模拟更大批次大小,提高训练稳定性
-
学习率调度:使用余弦退火策略动态调整学习率
-
目标网络:软更新目标网络提高训练稳定性
2.2 注意力机制设计
2.2.1 自注意力机制 (SelfAttention)
class SelfAttention(nn.Module):
def forward(self, x):
# 处理输入维度
if x.dim() == 2:
x = x.unsqueeze(1) # 添加序列维度
batch_size, seq_len, _ = x.size()
# 计算Q, K, V
q = self.q_proj(x) # (batch_size, seq_len, embed_dim)
k = self.k_proj(x)
v = self.v_proj(x)
# 多头注意力计算
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 应用注意力权重
attended = torch.matmul(attn_weights, v)
attended = attended.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)
# 输出投影和残差连接
output = self.out_proj(attended)
output = self.layer_norm(output + x)
return output.squeeze(1) if x.size(1) == 1 else output
2.2.2 交叉注意力机制 (CrossAttention)
class CrossAttention(nn.Module):
def forward(self, query, key, value):
batch_size, query_len, _ = query.size()
_, key_len, _ = key.size()
_, value_len, _ = value.size()
# 计算Q, K, V
q = self.q_proj(query)
k = self.k_proj(key)
v = self.v_proj(value)
# 多头注意力计算
q = q.view(batch_size, query_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, key_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, value_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算交叉注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 应用注意力权重
attended = torch.matmul(attn_weights, v)
attended = attended.transpose(1, 2).contiguous().view(batch_size, query_len, self.embed_dim)
# 输出投影和残差连接
output = self.out_proj(attended)
output = self.layer_norm(output + query)
return output
2.2.3 注意力机制在CQ/QX预测中的应用
def forward(self, state: torch.Tensor):
# 特征提取和自注意力处理
features = self.feature_net(state)
features = self.self_attention(features)
shared_features = self.shared_net(features)
# CQ预测分支
batch_size = shared_features.shape[0]
# 创建课目和素质的嵌入
subject_embed = self.cq_subject_proj(torch.eye(NUM_SUBJECTS, device=self.device)).unsqueeze(0).repeat(batch_size, 1, 1)
quality_embed = self.cq_quality_proj(torch.eye(NUM_QUALITIES, device=self.device)).unsqueeze(0).repeat(batch_size, 1, 1)
# 特征投影
feature_proj = self.cq_feature_proj(shared_features).unsqueeze(1)
# 两级交叉注意力
cq_attended = self.cq_cross_attention1(feature_proj, subject_embed, subject_embed)
cq_attended = self.cq_cross_attention2(cq_attended, quality_embed, quality_embed)
# CQ矩阵预测
cq_flat = self.cq_predictor(cq_attended.squeeze(1))
cq_matrix = cq_flat.view(batch_size, NUM_SUBJECTS, NUM_QUALITIES)
cq_matrix = F.softmax(cq_matrix, dim=-1) # 沿素质维度归一化
# QX预测分支 (类似CQ分支)
# ...
return action_probs, state_value, cq_matrix, qx_matrix
2.3 环境设计
2.3.1 状态空间设计
状态空间包含以下维度:
-
用户基本信息:年龄(1维)、性别(1维)、健身水平(1维)
-
当前素质水平:5维 (耐力、柔韧性、敏捷性、爆发力、力量)
-
课目成绩:93维 (对应93个课目)
-
目标课目编码:93维 (one-hot编码)
-
性能指标:4维 (最近改进、受伤风险、训练效率、一致性)
总状态维度:1+1+1+5+93+93+4 = 198维
2.3.2 动作空间设计
动作空间由两部分组成:
-
CQ矩阵调整:93(课目) × 5(素质) = 465种动作
-
QX矩阵调整:5(素质) × 44(动作) = 220种动作
总动作空间:465 + 220 = 685种动作
2.3.3 奖励函数设计
def _calculate_reward(self) -> float:
# 计算目标课目达成分数
target_scores = {}
for subject in self.current_state.target_subjects:
subject_idx = SUBJECTS.index(subject)
subject_score = 0.0
for q_idx, quality_score in enumerate(self.current_state.current_qualities):
subject_score += self.cq_matrix[subject_idx, q_idx] * quality_score
target_scores[subject] = subject_score
# 平均目标分数
avg_target_score = sum(target_scores.values()) / len(target_scores) if target_scores else 0.0
# 计算权重矩阵变化幅度 (惩罚项)
cq_diff = torch.norm(self.cq_matrix - self.initial_cq_matrix).item()
qx_diff = torch.norm(self.qx_matrix - self.initial_qx_matrix).item()
# 组合奖励
reward = avg_target_score - 0.01 * (cq_diff + qx_diff)
return reward
奖励函数设计特点:
-
目标导向:奖励与目标课目达成分数正相关
-
稳定性约束:惩罚权重矩阵的大幅变化
-
平衡性:通过系数0.01平衡目标达成和稳定性
2.3.4 状态转移设计
def step(self, action: torch.Tensor) -> Tuple[torch.Tensor, float, bool, Dict]:
# 解析动作
action_idx = torch.argmax(action).item()
matrix_type = action_idx // (NUM_SUBJECTS * NUM_QUALITIES + NUM_QUALITIES * NUM_ACTIONS)
if matrix_type == 0: # CQ矩阵调整
position_idx = action_idx % (NUM_SUBJECTS * NUM_QUALITIES)
row = position_idx // NUM_QUALITIES
col = position_idx % NUM_QUALITIES
# 微调权重并归一化
adjustment = (torch.rand(1, device=device).item() - 0.5) * 0.1
self.cq_matrix[row, col] += adjustment
self.cq_matrix[row, col] = max(0.0, min(1.0, self.cq_matrix[row, col]))
self.cq_matrix[row] = self.cq_matrix[row] / self.cq_matrix[row].sum()
else: # QX矩阵调整 (类似处理)
# ...
# 计算奖励
reward = self._calculate_reward()
# 创建新状态
new_state = self._create_new_state()
return new_state.to_tensor().to(device), reward, done, {}
3. 训练策略设计
3.1 多阶段训练策略
3.1.1 预训练阶段
-
初始化权重矩阵:基于目标课目调整CQ矩阵初始权重
-
特征提取:使用预训练的特征提取网络
-
注意力机制初始化:使用Xavier初始化注意力参数
3.1.2 主训练阶段
def train_optimized(self, env, training_data, episodes=1000, ...):
# 初始化
scaler = torch.cuda.amp.GradScaler(enabled=use_amp and device.type == 'cuda')
# 训练循环
for episode in range(episodes):
# 选择训练样本
sample_idx = episode % len(training_data)
sample = training_data[sample_idx]
# 创建初始状态
initial_state = State(...)
# 重置环境
state = env.reset(initial_state)
# 收集轨迹
states, actions, rewards, log_probs, values, cq_preds, qx_preds = [], [], [], [], [], [], []
# 执行一个回合
for step in range(max_steps_per_episode):
# 选择动作
action, log_prob, cq_pred, qx_pred = self.select_action(state, training=True)
# 执行动作
next_state, reward, done, _ = env.step(torch.zeros(self.action_dim, device=device))
# 存储轨迹
states.append(state)
actions.append(action)
rewards.append(reward)
log_probs.append(log_prob)
cq_preds.append(cq_pred)
qx_preds.append(qx_pred)
# 获取价值估计
with torch.no_grad():
_, value, _, _ = self.actor_critic(state)
values.append(value.item())
state = next_state
if done:
break
# 计算回报和优势
returns, advantages = self._compute_returns_and_advantages(
rewards, values, dones, self.gamma, last_value.item()
)
# 转换为张量
states = torch.stack(states).to(device)
actions = torch.tensor(actions, dtype=torch.long, device=device)
returns = torch.tensor(returns, dtype=torch.float32, device=device)
advantages = torch.tensor(advantages, dtype=torch.float32, device=device)
log_probs = torch.tensor(log_probs, dtype=torch.float32, device=device)
# 标准化优势
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# 多次更新
for i in range(10):
with torch.cuda.amp.autocast(enabled=use_amp and device.type == 'cuda'):
# 计算损失
action_probs, values, cq_pred, qx_pred = self.actor_critic(states)
dist = Categorical(action_probs)
new_log_probs = dist.log_prob(actions)
ratio = torch.exp(new_log_probs - log_probs)
# PPO损失
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - self.clip_ratio, 1.0 + self.clip_ratio) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
# 价值损失
value_loss = F.smooth_l1_loss(values.squeeze(), returns)
# CQ损失
true_cq = env.cq_matrix.unsqueeze(0).repeat(len(states), 1, 1)
cq_loss = torch.mean(F.mse_loss(cq_pred, true_cq, reduction='none')) * 50
# QX损失
true_qx = env.qx_matrix.unsqueeze(0).repeat(len(states), 1, 1)
qx_loss = torch.mean(F.mse_loss(qx_pred, true_qx, reduction='none')) * 100
# 熵损失
entropy = dist.entropy().mean()
entropy_loss = -self.entropy_coef * entropy
# 总损失
loss = (actor_loss +
self.value_loss_coef * value_loss +
entropy_loss +
self.cq_loss_coef * cq_loss +
self.qx_loss_coef * qx_loss)
# 反向传播
loss = loss / gradient_accumulation_steps
scaler.scale(loss).backward()
# 梯度累积和更新
if (i + 1) % gradient_accumulation_steps == 0:
# 梯度裁剪
if use_amp and device.type == 'cuda':
scaler.unscale_(self.actor_optimizer)
scaler.unscale_(self.critic_optimizer)
scaler.unscale_(self.cq_optimizer)
scaler.unscale_(self.qx_optimizer)
torch.nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm)
# 更新优化器
scaler.step(self.actor_optimizer)
scaler.step(self.critic_optimizer)
scaler.step(self.cq_optimizer)
scaler.step(self.qx_optimizer)
scaler.update()
# 清零梯度
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
self.cq_optimizer.zero_grad()
self.qx_optimizer.zero_grad()
# 更新学习率和探索率
actor_scheduler.step()
critic_scheduler.step()
cq_scheduler.step()
qx_scheduler.step()
self.epsilon = max(self.epsilon_min, self.epsilon * self.epsilon_decay)
# 更新目标网络
self.update_target_network()
# 早停检查
# ...
3.1.3 微调阶段
-
降低学习率:使用更小的学习率进行精细调整
-
调整损失权重:增加CQ和QX预测的损失权重
-
减少探索:降低ε-贪心中的ε值
3.2 学习率调度策略
# 余弦退火学习率调度器
actor_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.actor_optimizer, T_max=episodes, eta_min=1e-6
)
critic_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.critic_optimizer, T_max=episodes, eta_min=1e-5
)
cq_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.cq_optimizer, T_max=episodes, eta_min=1e-6
)
qx_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.qx_optimizer, T_max=episodes, eta_min=1e-6
)
学习率调度特点:
-
余弦退火:学习率按余弦函数从初始值衰减到最小值
-
不同组件不同调度:Actor、Critic、CQ和QX使用不同的最小学习率
-
周期性调整:每个训练周期后更新学习率
3.3 早停策略
# 早停变量
best_avg_reward = float('-inf')
best_cq_accuracy = 0.0
best_qx_accuracy = 0.0
best_total_loss = float('inf')
patience_counter = 0
# 早停检查
recent_rewards = self.episode_rewards[-min(10, len(self.episode_rewards)):]
avg_reward = sum(recent_rewards) / len(recent_rewards) if recent_rewards else 0
total_loss = avg_actor_loss + avg_critic_loss + avg_cq_loss + avg_qx_loss
if (avg_reward > best_avg_reward or
cq_accuracy > best_cq_accuracy or
qx_accuracy > best_qx_accuracy or
total_loss < best_total_loss):
# 更新最佳指标
if avg_reward > best_avg_reward:
best_avg_reward = avg_reward
if cq_accuracy > best_cq_accuracy:
best_cq_accuracy = cq_accuracy
if qx_accuracy > best_qx_accuracy:
best_qx_accuracy = qx_accuracy
if total_loss < best_total_loss:
best_total_loss = total_loss
# 保存最佳模型
torch.save(self.actor_critic.state_dict(), "models9/enhanced_ppo_agent_attention_best.pth")
# 重置耐心计数器
patience_counter = 0
else:
patience_counter += 1
# 检查是否早停
if patience_counter >= early_stop_patience:
logger.info(f"Early stopping at episode {episode}")
break
早停策略特点:
-
多指标评估:同时考虑奖励、准确率和损失
-
耐心机制:允许连续多个回合不改进才停止
-
最佳模型保存:保存性能最好的模型
4. 关键优化技术
4.1 混合精度训练
# 创建GradScaler
scaler = torch.cuda.amp.GradScaler(enabled=use_amp and device.type == 'cuda')
# 在自动混合精度下计算损失
with torch.cuda.amp.autocast(enabled=use_amp and device.type == 'cuda'):
# 前向计算
action_probs, values, cq_pred, qx_pred = self.actor_critic(states)
# 损失计算
loss = ...
# 缩放损失并反向传播
scaler.scale(loss).backward()
# 梯度裁剪
if use_amp and device.type == 'cuda':
scaler.unscale_(optimizer)
# 更新参数
scaler.step(optimizer)
scaler.update()
混合精度训练优势:
-
加速训练:使用FP16加速矩阵运算
-
减少内存:FP16占用内存更少
-
保持精度:动态损失缩放防止梯度下溢
4.2 梯度累积
gradient_accumulation_steps = 4
for i in range(10):
# 计算损失
loss = ...
# 缩放损失用于梯度累积
loss = loss / gradient_accumulation_steps
# 反向传播
scaler.scale(loss).backward()
# 只在累积了一定步数后更新权重
if (i + 1) % gradient_accumulation_steps == 0:
# 梯度裁剪和参数更新
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
梯度累积优势:
-
模拟大批次:小内存设备可模拟大批次训练
-
稳定训练:减少梯度方差,提高训练稳定性
-
灵活调整:可根据内存情况调整累积步数
4.3 权重矩阵初始化优化
def reset(self, initial_state: State) -> torch.Tensor:
# 初始化权重矩阵
self.initial_cq_matrix = torch.ones(NUM_SUBJECTS, NUM_QUALITIES, device=device) / NUM_QUALITIES
self.initial_qx_matrix = torch.ones(NUM_QUALITIES, NUM_ACTIONS, device=device) / NUM_ACTIONS
# 【优化点1】对CQ矩阵进行预处理,基于目标课目调整初始权重
for subject in initial_state.target_subjects:
subject_idx = SUBJECTS.index(subject)
# 对目标课目相关的素质给予更高初始权重
self.initial_cq_matrix[subject_idx] = torch.rand(NUM_QUALITIES, device=device)
self.initial_cq_matrix[subject_idx] = self.initial_cq_matrix[subject_idx] / self.initial_cq_matrix[subject_idx].sum()
self.cq_matrix = self.initial_cq_matrix.clone()
self.qx_matrix = self.initial_qx_matrix.clone()
return initial_state.to_tensor().to(device)
初始化优化特点:
-
目标导向:根据目标课目调整初始权重
-
随机性:使用随机初始化增加多样性
-
归一化:确保权重和为1
4.4 损失函数设计优化
# 【优化点9】计算CQ预测损失 - 使用加权MSE和更小的损失权重
true_cq = env.cq_matrix.unsqueeze(0).repeat(len(states), 1, 1)
cq_weights = torch.ones_like(true_cq) # 可以根据需要调整权重
cq_loss = torch.mean(cq_weights * F.mse_loss(cq_pred, true_cq, reduction='none')) * 50 # 减小损失权重
# 计算QX预测损失 - 使用加权MSE
true_qx = env.qx_matrix.unsqueeze(0).repeat(len(states), 1, 1)
qx_weights = torch.ones_like(true_qx) # 可以根据需要调整权重
qx_loss = torch.mean(qx_weights * F.mse_loss(qx_pred, true_qx, reduction='none')) * 100
损失函数优化特点:
-
加权MSE:可对不同元素赋予不同重要性
-
损失权重调整:CQ损失权重50,QX损失权重100
-
扩展性:可根据需要添加更复杂的权重策略
5. API服务设计
5.1 权重优化服务
@app.post("/optimize_weights", response_model=WeightOptimizationResponse)
async def optimize_weights(request: WeightOptimizationRequest):
# 创建初始状态
initial_state = State(
user_id=request.user_id,
age=request.age,
gender=request.gender,
fitness_level=request.fitness_level,
current_qualities=request.current_qualities,
target_subjects=request.target_subjects,
subject_scores=[0.5] * NUM_SUBJECTS, # 默认值
performance_metrics={
"recent_improvement": 0.0,
"injury_risk": 0.0,
"training_efficiency": 0.5,
"consistency": 0.5
}
)
# 重置环境
state = env.reset(initial_state)
# 优化循环
for step in range(request.optimization_steps):
# 选择动作
action, _, cq_pred, qx_pred = model_optimizer.select_action(state, training=False)
# 执行动作
state, _, done, _ = env.step(torch.zeros(model_optimizer.action_dim, device=device))
if done:
break
# 获取最终权重矩阵
cq_matrix = env.cq_matrix.cpu().numpy().tolist()
qx_matrix = env.qx_matrix.cpu().numpy().tolist()
# 计算目标课目达成分数
target_achievement_scores = {}
for subject in request.target_subjects:
subject_idx = SUBJECTS.index(subject)
subject_score = 0.0
for q_idx, quality_score in enumerate(request.current_qualities):
subject_score += cq_matrix[subject_idx][q_idx] * quality_score
target_achievement_scores[subject] = subject_score
# 计算性能指标
performance_metrics = {
"cq_matrix_norm": np.linalg.norm(cq_matrix),
"qx_matrix_norm": np.linalg.norm(qx_matrix),
"optimization_steps": step + 1
}
# 返回响应
return WeightOptimizationResponse(
user_id=request.user_id,
optimization_timestamp=datetime.now().isoformat(),
cq_matrix=cq_matrix,
qx_matrix=qx_matrix,
performance_metrics=performance_metrics,
target_achievement_scores=target_achievement_scores
)
5.2 权重预测服务
@app.post("/predict_weights", response_model=WeightPredictionResponse)
async def predict_weights(request: WeightPredictionRequest):
# 创建状态
state = State(
user_id=request.user_id,
age=request.age,
gender=request.gender,
fitness_level=request.fitness_level,
current_qualities=request.current_qualities,
target_subjects=request.target_subjects,
subject_scores=request.subject_scores if request.subject_scores else [0.5] * NUM_SUBJECTS,
performance_metrics=request.performance_metrics if request.performance_metrics else {
"recent_improvement": 0.0,
"injury_risk": 0.0,
"training_efficiency": 0.5,
"consistency": 0.5
}
)
# 转换为张量
state_tensor = state.to_tensor().to(device)
# 预测权重
cq_matrix, qx_matrix, confidence = model_optimizer.predict_weights(state_tensor)
# 转换为列表
cq_matrix = cq_matrix.cpu().numpy().tolist()
qx_matrix = qx_matrix.cpu().numpy().tolist()
# 计算目标课目达成分数
target_achievement_scores = {}
for subject in request.target_subjects:
subject_idx = SUBJECTS.index(subject)
subject_score = 0.0
for q_idx, quality_score in enumerate(request.current_qualities):
subject_score += cq_matrix[subject_idx][q_idx] * quality_score
target_achievement_scores[subject] = subject_score
# 返回响应
return WeightPredictionResponse(
user_id=request.user_id,
prediction_timestamp=datetime.now().isoformat(),
cq_matrix=cq_matrix,
qx_matrix=qx_matrix,
target_achievement_scores=target_achievement_scores,
prediction_confidence=confidence
)
5.3 模型训练服务
@app.post("/train", response_model=TrainingResponse)
async def train_model(request: TrainingRequest, background_tasks: BackgroundTasks):
# 在后台执行训练
background_tasks.add_task(
train_model_background,
request.episodes,
request.max_steps_per_episode,
request.save_path,
request.learning_rate,
request.gamma,
request.clip_ratio,
request.training_data,
request.batch_size,
request.shuffle_data,
request.early_stop_patience
)
# 返回响应
return TrainingResponse(
success=True,
model_path=request.save_path,
episodes_completed=0,
average_reward=0.0,
training_time_seconds=0.0,
message="Training started in background"
)
async def train_model_background(episodes, max_steps_per_episode, save_path, learning_rate,
gamma, clip_ratio, training_data, batch_size,
shuffle_data, early_stop_patience):
# 训练逻辑实现
# ...
6. 性能优化与监控
6.1 GPU内存管理
def get_gpu_memory_usage():
"""获取GPU内存使用情况"""
if torch.cuda.is_available():
allocated = torch.cuda.memory_allocated() / (1024 ** 3) # GB
cached = torch.cuda.memory_reserved() / (1024 ** 3) # GB
max_allocated = torch.cuda.max_memory_allocated() / (1024 ** 3) # GB
return {
"allocated": allocated,
"cached": cached,
"max_allocated": max_allocated
}
return None
# 在训练循环中监控GPU内存
if episode % 10 == 0:
gpu_memory = get_gpu_memory_usage()
if gpu_memory:
logger.info(f"GPU Memory - Allocated: {gpu_memory['allocated']:.2f}GB, "
f"Cached: {gpu_memory['cached']:.2f}GB, "
f"Max Allocated: {gpu_memory['max_allocated']:.2f}GB")
# 清理CUDA缓存
if device.type == 'cuda':
torch.cuda.empty_cache()
6.2 训练指标监控
# 训练统计指标
self.episode_rewards = []
self.episode_lengths = []
self.actor_losses = []
self.critic_losses = []
self.entropy_losses = []
self.value_losses = []
self.gradient_norms = []
self.learning_rates = []
self.exploration_rates = []
self.cq_losses = []
self.cq_accuracies = []
self.qx_losses = []
self.qx_accuracies = []
# 计算准确率
def _calculate_cq_accuracy(self, pred, target):
"""计算CQ矩阵预测准确率"""
# 使用余弦相似度作为准确率指标
pred_flat = pred.view(-1)
target_flat = target.view(-1)
similarity = F.cosine_similarity(pred_flat, target_flat, dim=0)
return (similarity + 1) / 2 # 将[-1,1]映射到[0,1]
def _calculate_qx_accuracy(self, pred, target):
"""计算QX矩阵预测准确率"""
# 使用余弦相似度作为准确率指标
pred_flat = pred.view(-1)
target_flat = target.view(-1)
similarity = F.cosine_similarity(pred_flat, target_flat, dim=0)
return (similarity + 1) / 2 # 将[-1,1]映射到[0,1]
6.3 日志与异常处理
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("weight_optimization_attention.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
# 异常处理
@app.exception_handler(Exception)
async def global_exception_handler(request: Request, exc: Exception):
logger.error(f"Unhandled exception: {str(exc)}", exc_info=True)
return JSONResponse(
status_code=500,
content={"error": "Internal server error", "detail": str(exc)}
)
7. 系统部署与扩展
7.1 部署架构
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ Load Balancer │ │ API Gateway │ │ Monitoring │ └────────┬────────┘ └────────┬────────┘ └────────┬────────┘ │ │ │ └──────────────────────┼──────────────────────┘ │ ┌──────────────────────┼──────────────────────┐ │ │ │ ┌────────▼────────┐ ┌────────▼────────┐ ┌────────▼────────┐ │ API Instance 1 │ │ API Instance 2 │ │ API Instance N │ │ (FastAPI) │ │ (FastAPI) │ │ (FastAPI) │ └────────┬────────┘ └────────┬────────┘ └────────┬────────┘ │ │ │ └──────────────────────┼──────────────────────┘ │ ┌───────────▼───────────┐ │ Model Storage │ │ (Shared Volume) │ └───────────────────────┘
7.2 扩展性设计
-
水平扩展:通过增加API实例数量提高系统吞吐量
-
模型版本管理:支持多版本模型并存和热切换
-
分布式训练:支持多GPU分布式训练大规模模型
-
缓存策略:对频繁请求的用户状态进行缓存
7.3 监控与告警
-
性能监控:监控API响应时间、吞吐量、错误率
-
资源监控:监控CPU、内存、GPU使用情况
-
业务监控:监控优化效果、预测准确率等业务指标
-
告警机制:设置阈值告警,及时发现系统异常
8. 总结
该体能训练权重优化系统通过以下关键技术实现了高性能的权重优化服务:
-
先进的强化学习算法:基于增强PPO算法,结合注意力机制和残差网络
-
多目标优化:同时优化策略、价值、CQ预测和QX预测四个目标
-
高效的训练策略:混合精度训练、梯度累积、学习率调度、早停机制
-
精心设计的奖励函数:平衡目标达成和权重稳定性
-
完善的API服务:提供权重优化、预测和训练三种核心服务
-
全面的性能优化:GPU内存管理、训练监控、异常处理
该系统能够根据用户的当前素质水平和目标课目,智能优化课目-素质权重矩阵和素质-动作权重矩阵,为个性化体能训练提供科学依据,具有很高的实用价值和推广前景。
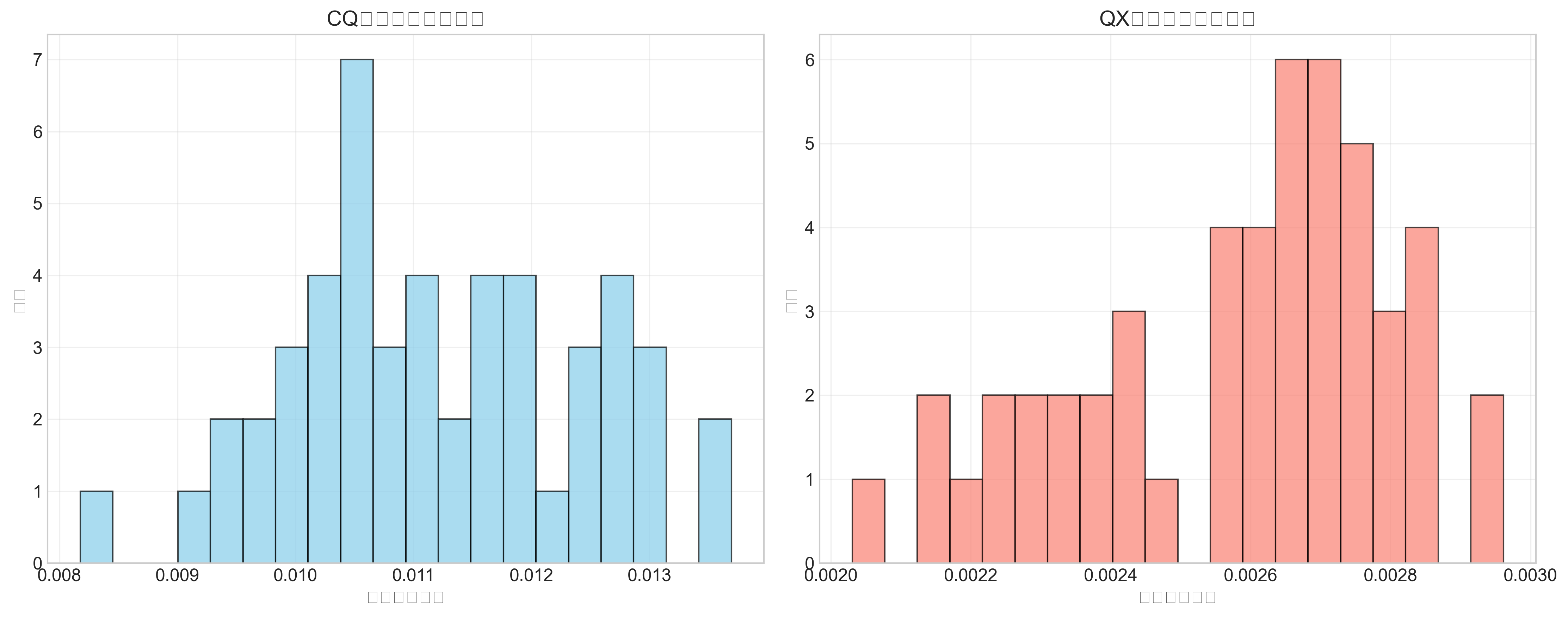
=== 评估指标 ===CQ矩阵 MSE: 0.000470
CQ矩阵 MAE: 0.011198
CQ矩阵 RMSE: 0.021680
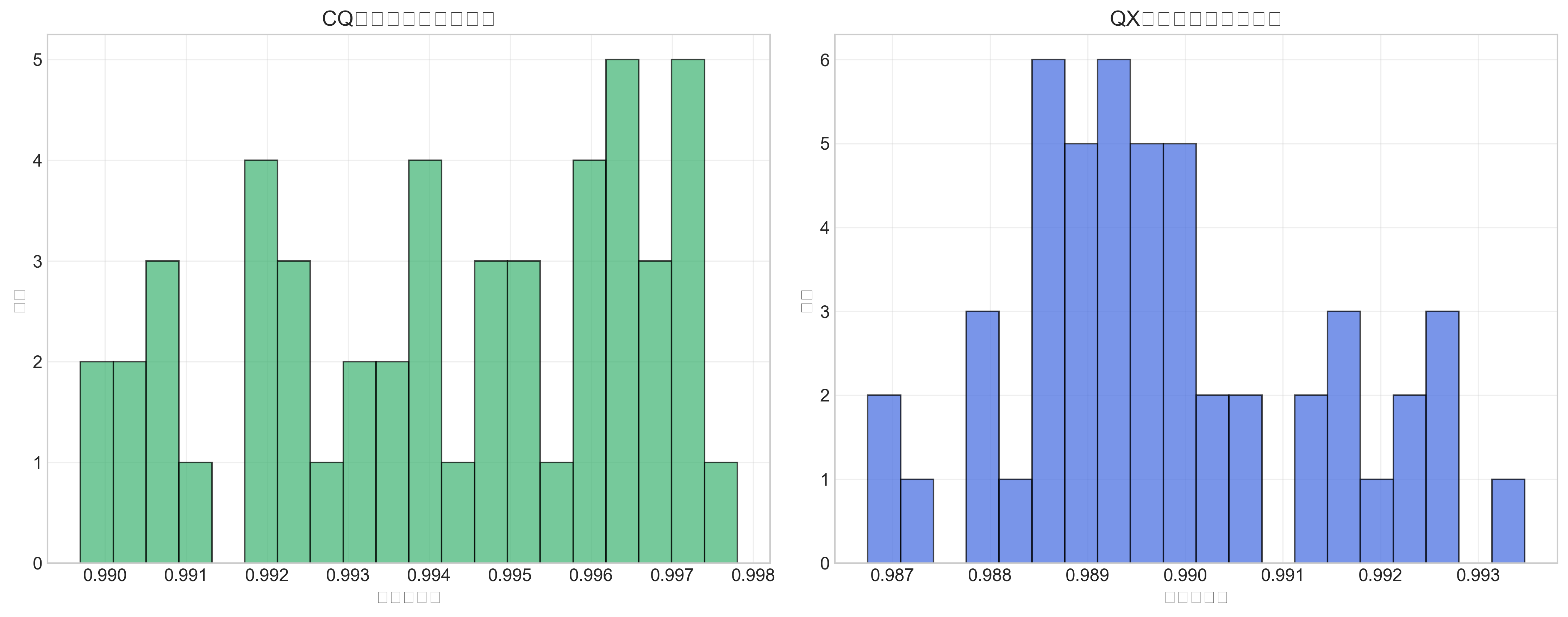
CQ矩阵平均余弦相似度: 0.994171
CQ矩阵平均Pearson相关系数: 0.005456
QX矩阵 MSE: 0.000011
QX矩阵 MAE: 0.002580
QX矩阵 RMSE: 0.003270
QX矩阵平均余弦相似度: 0.989808
QX矩阵平均Pearson相关系数: nan
平均置信度: 0.981191
CQ置信度-误差相关性: 0.074356
QX置信度-误差相关性: -0.033683